
SpenDB, a light-weight tool for government financial data
03 June 2015
One day I will find the right words, and they will be simple. - Jack Kerouac
SpenDB is a prototype-stage, light-weight data loading tool and analytical API for government financial data. Over the past few months, I have spent my weekends simplifying and modernizing the OpenSpending codebase to create this tool.
So far, I’ve been able to make it easier for non-technical users to submit and model data, to introduce a more systematic process for data management (based on loadkit and archivekit) and to upgrade to a newer stack of technologies (Flask, Angular and Bootstrap 3).
Simplifying the mammoth
The biggest conceptual change is the data loading process, which now accepts file uploads, stores all source and cleaned data on Amazon and changes the way that models are applied to the data so that the OLAP description of the data can be produced and changed after data loading is complete.
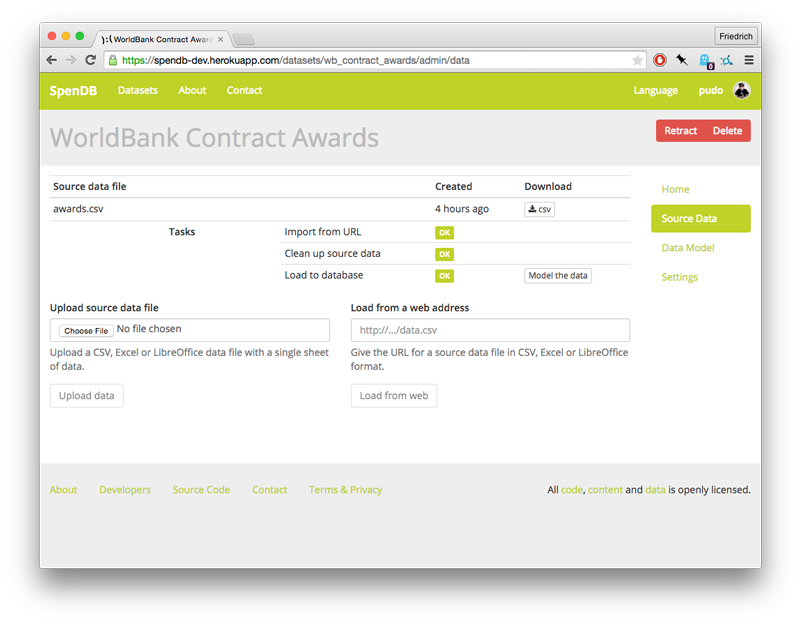
Beyond that, SpenDB uses Stefan Urbanek’s excellent Cubes for its analytics API. The tool supports a richer set of query operations and has its own growing community. This change, and dropping many non-essential features, allowed the code to shrink down to a quarter of that in OpenSpending.
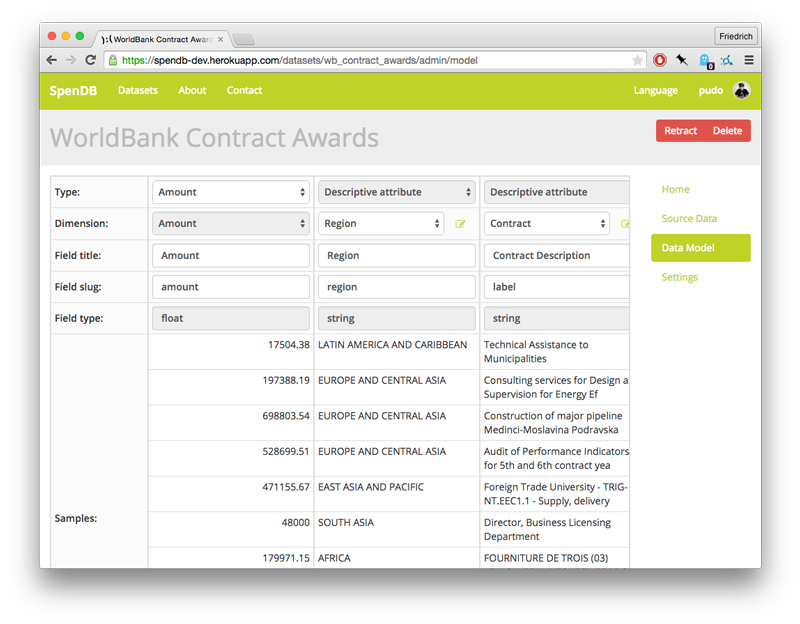
Unfortunately, two months into these changes, Open Knowledge adopted another strategy - now called Next - for the OpenSpending project. It is focused on providing developers with a data catalogue and mirco-services, rather than producing a coherent, user-facing experience.
Focus on usability and data analysis
While SpenDB may eventually find its place in OpenSpending Next, I want to focus my contributions on the issues underlying much of the user feedback I’ve seen in the last four years. This means making loading data into the platform incredibly easy, and providing meaningful ways to study the available budgets, expenditures and contract awards.
Thus far, SpenDB solves neither of these challenges, but it creates a great starting point: the new loading architecture makes it easy to iterate on the user experience for data submission, and the Cubes API will allow query and visualization tools to connect not just to SpenDB, but also to other Cubes-based projects, like ReGENESIS (German national statistics).
To test my work, I plan to migrate OffenerHaushalt to the new API, so that German budget cartographers can provide feedback on the data loading workflow. Once analytical tools are developed, the European contract awards in OpenTED and research funding in Germany’s Förderkatalog will be great testing datasets for pivot tables and aggregate search functionality.
Eventually, I’m hoping to also produce a generalized version of Mark Brough’s Aid Budget Mapper, a tool for taxonomy alignment which provides the foundation for a crowd-sourced budget comparison initiative.
Call for contributions
Hacking on SpenDB has been extremely fun and instructive, it’s a microcosm of web-based business intelligence applications. Now that the core is relatively stable, the focus will shift towards user experience, design and making great data analysis tools.
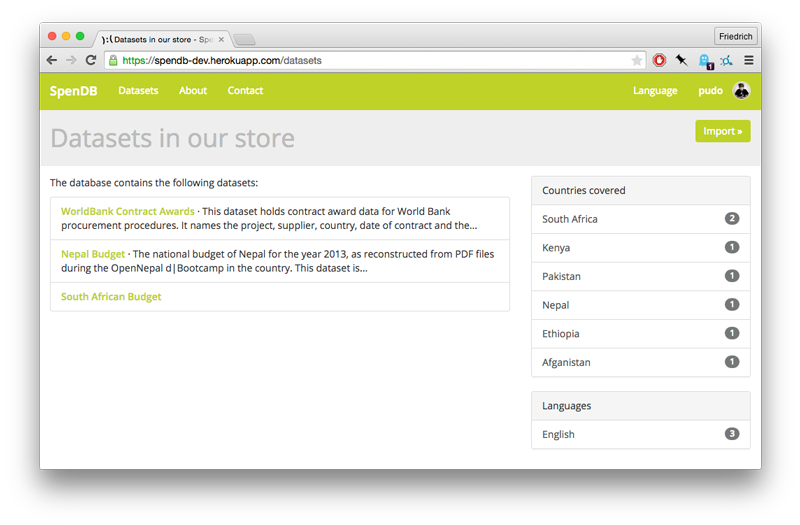
For anyone who is looking for a cool data project to cut their teeth on, there is plenty to do here:
- Build a great Cubes-based implementation of a pivot tables-like data browser.
- Generate, capture and reflect user feedback for the data loading process.
- Come up with a simple but useful way to sift through datasets and to make sure they are always up to date and complete.
- Design beautiful bar charts, line graphs, pie charts, treemaps and slope graphs.
- Documentation that is accessible, useful and detailed
Obviously, this list is a personal wish-list, but SpenDB should do whatever you think is needed to crack the nut of practical budget and fiscal transparency for a broader audience. Come hack!
Where to get started
- Repository on GitHub with the issue tracker.
- Development instance deployed to Heroku free tier.
- Aggregate API and Cubes documentation.