
datawi.re: when the data mountain comes to you
06 November 2013
For a few months now, Annabel and I have been working on datawi.re, an effort to create a better way for journalists to keep track of data feeds.

The tool would create a simple way for users to list people, companies and institutions that they want to track across different sources of data. Such sources could include government feeds for procurement, spending or public journals, or other public data such as corporate ownership information.
One benefit of such a tool would be to make more public data accessible to end-users at the time when it first appears online by feeding the latest scraper output directly into datawi.re. Any data source could be hooked up to datawi.re, allowing for connections between data feeds to be revealed across a broadening repertoire of data. It would also encourage journalists to become more systematic creating sets of people and organisations that are of interest to them.
Unfortunately, this is not a launch post. While the datawi.re prototype is functional, it is also clear that - on a fairly fundamental level - it doesn’t yet do the right thing.
The first mistake we made with datawi.re, I believe, was its choice of metaphor: datawi.re would provide an interface similar to that of Twitter, allowing users to ‘follow’ people and organizations across data feeds. The data itself was templated into short text snippets to prevent the service from bombarding users with tabular nonsense.
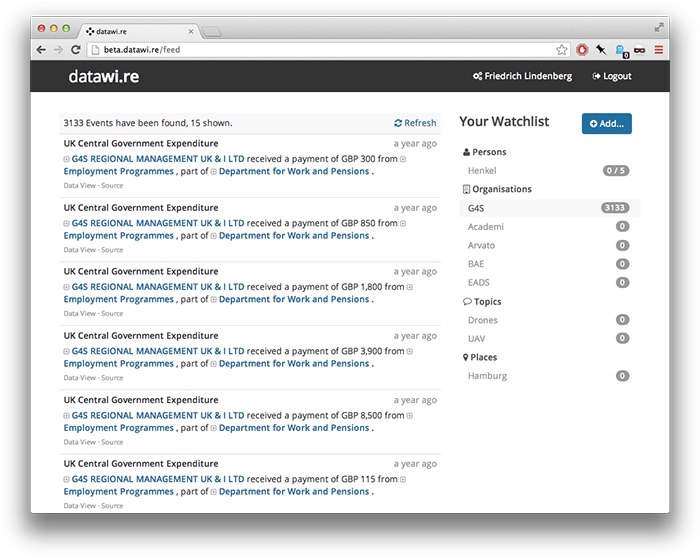
This model has a number of advantages: fully streamed messages don’t require datawi.re to know much about the structure and semantics of each data source. Essentially it would just grep through the data and then render matching data records in the user’s browser. It was important to me that datawi.re should not become another data catalogue or data warehouse, and using a streaming metaphor seemed like a convenient way of avoiding deep interaction with the data.
On the other hand, the stream nature of datawi.re also meant that the service could not easily perform any aggregate analysis on the data - such as trend and outlier detection. A government contract for 500 EUR would be shown with the same weight as one for 500 Million EUR. Essentially, datawi.re would be able to detect the topic of a data item, but without seeing any context and having an understanding of the data, it would inevitably fail to estimate it’s significance.
Another issue with the stream is the difficulty that users have in discovering entities to track. They don’t have good visibility on the existing data, as matches only show up for existing search words. In the full data stream, there are simply too many options, and identifying the overlaps between what a user is interested in and what can reasonably surfaced in a dataset is a hard task. It is in fact, it is probably the core activity of much of journalism.
One final issue for datawi.re is the lack of data infrastructure to support it. While the site itself doesn’t need to know too much about the data sources feeding into it, each source needs to be set up individually to submit data to datawi.re. Still, we don’t know very much about whether a data source is still active or in need of maintenance. It would be great if datawi.re didn’t have to build all of this infrastructure but could plug into an existing system, such as Max Ogden’s dat.
All of this is not to say that datawi.re is dead, but I think the project needs to be significantly re-engineered to overcome these issues. To that end, I’m hoping to go back to the drawing board and collect a larger set of specific use cases - each including the specific dataset, search criteria and matching heuristic for a data notification service that is actually able to surface meaningful matches.
Of course, datawi.re is available as an open source codebase for everyone to play with, and I’m keen to hear any ideas that people may have for the direction in which it should be carried next.