
Notes: Crunching text documents for fun and knowledge
01 July 2013
One exciting development at Spiegel is the recent introduction of a weekly data journalism workshop that brings together reporters, fact checkers and designers from both the print and online sections of the organisation.
This week’s workshop will focus on dealing with large collections of documents, so I took some time on Monday to experiment with a few different text mining components. My goal was to find usable tool that include an accessible interface rather than pure APIs and libraries. My interest in this was greatly enhanced after meeting Jonathan Stray at the Civic Media Conference last week and learning about his Overview project.
As a working dataset, I chose the parliamentary documents - bills, transcripts and other business - of the German Bundestag; a set of about 22,000 PDF files covering a wide range of topics and formal structures. Using a German dataset made for an additional challenge, as many linguistics toolkits support only Spanish, French and, of course, English.
Content extraction with Tika
After downloading, I hoped to use Apache Tika to mass convert the documents to plain text for further processing. While Tika supports a wide range of different formats, it appears to be focussed on converting individual files rather than crawling folders. Its user interface is fun to play with, but I’m not sure it has any real world applications. And while Tika has a server mode, it’s based on piping data in via raw TCP/IP. I was unable to have it convert any documents. Starting (nay, booting) Tika for each document seemed like a waste of time.
Stanbol to the rescue
My dilemma was eventually solved by Apache Stanbol, which fellow fellow Manuel had recommended I should try out. This project seems to have the goal of using linked data to glue up as many natural language processing libraries as they can fit into a single Java container. As part of this software smörgåsbord, the maintainers have included a REST API for Tika which can return either a document’s plain text or its metadata.
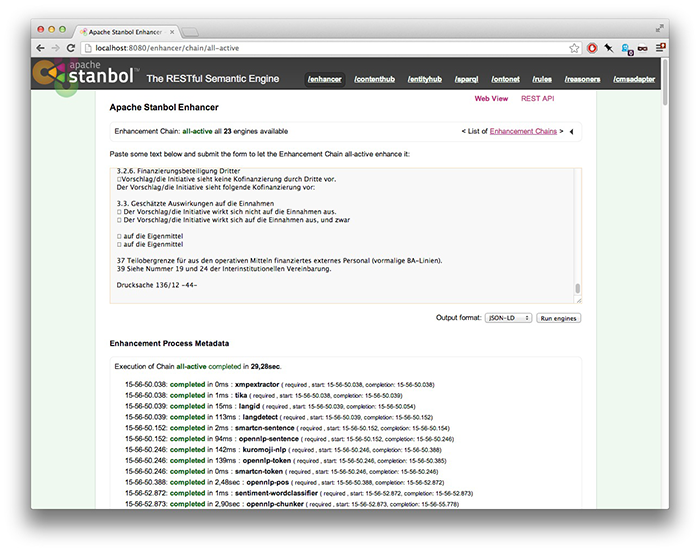
While hardly a non-techie solution, this allowed me to script up a CSV file containing each document’s title, text, source URL and modification date. I’m still hoping to try this type of bulk conversion out on a set of documents in more diverse formats, but I’m very optimistic about Tika’s ability to crack open some Word documents.
Stanbol also integrates a wide range of other language processing and entity extraction tools via a set of configurable processing pipelines. I’m not sure the benefits of a REST API on top of these services really makes up for the additional integration work required by its RDF output format.
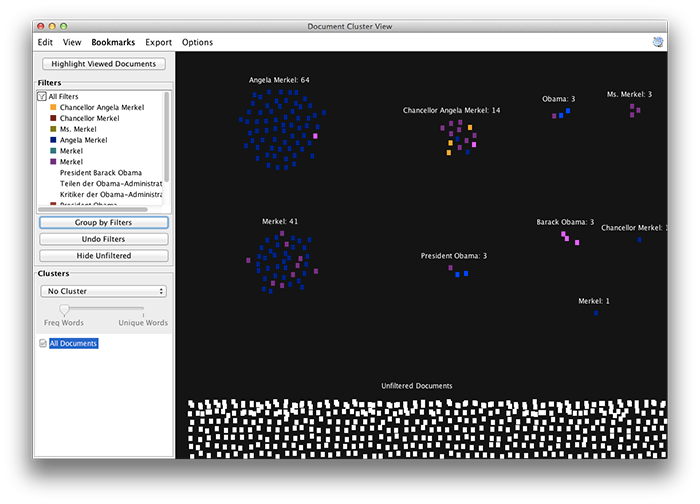
Jigsaw: Entities, visualized
Jigsaw is a visual analytics tool developed by researchers at Georgia Tech, which I’d heard about from Sebastian. While the software allows imports from a range of formats, its scalability seems to be quite limited. I had to shrink my document set down to about a hundred Bundestag documents to achieve an acceptable level of responsiveness. This may be related to document size, however, as I later had a much better experience using a set of 1000 Spiegel Online news stories.
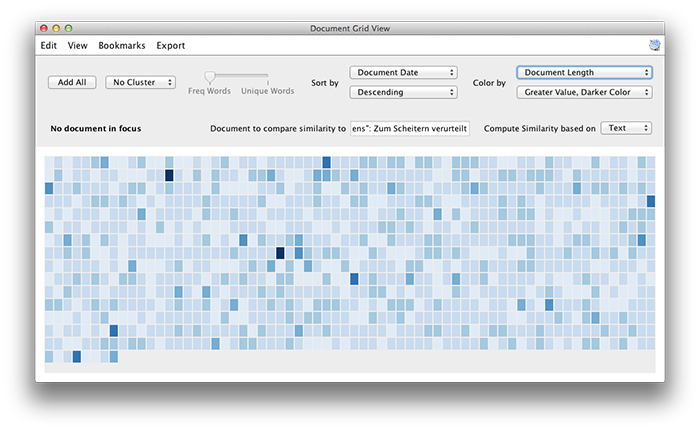
The Jigsaw interface is the type of thing that will make you want to tear out your own eyeballs, but there is a set of tutorial videos which help to alleviate the pain. Once you get the hang of it, though, the package turns out to be fairly useful with a broad variety of visual methods for slicing, dicing and sorting the document set.
Entity extraction underlies much of Jigsaw’s functionality, so the lack of support for the German language really comes to bear on this tool. Still, it supports a variety of extractors, including Reuters’ OpenCalais web service. Even for English documents, I didn’t see any support for the normalization of extracted entities, so “Edward Snowden”, “Mr. Snowden” and “Edward J Snowden” remain separate.
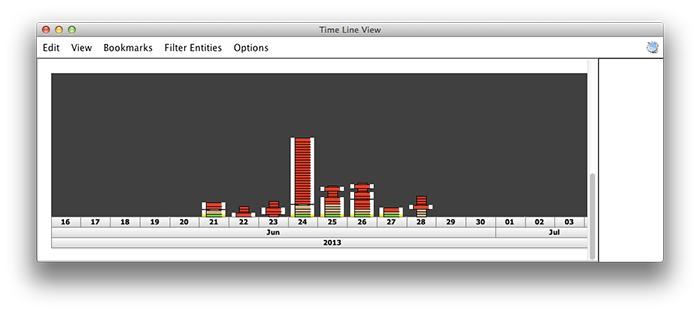
The different views of Jigsaw - graphs, time lines, and various clever listings - are well thought out, but on the whole, it remains a research tool that would require some productization before being ready for day-to-day use.
Pretend its not programming
KNIME is the most comprehensive data and text processing tool I looked at, which is probably also its weakness in the face of journalists. The tool, while certainly a fully-fleged data workflow editor, seems to be based on the belief that the hard part about programming is learning the syntax. What the point and click interface enables is essentially coding, even though it comes in the shape of menus, tabs and dropdowns.
Still, I enjoyed the tools documentation sidebar, which gives nice primers on the indivdual processing nodes, including some statistical methods.
Overview
As mentioned above, I was especially interested in Overview. Like OpenSpending, the project was a winner of the Knight News Challenge in 2011 funded to build out some experimental tools used for the WikiLeaks cables inside the AP. Made for the newsroom, Overview directly integrates with DocumentCloud and features a simple and clean web interface.
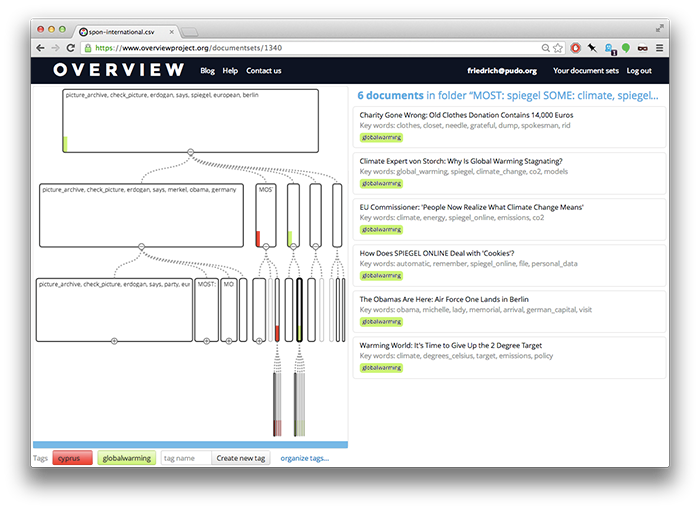
Unlike Jigsaw, Overview makes no use of entity extraction and relies entirely on term frequencies in documents. Documents are visually clustered by showing characteristic terms for document groups in a tree structure. While this provides a neat way to dissect a document set, it is also the only means of navigation. In Boston, Jonathan mentioned they were about to add a second view to support time-based analysis. Still, this is a far cry from the variety of visual facets provided by Jigsaw or Nuix.
Overview’s frequency-based approach is quite prone to highlight the specific lingo used in a set of documents. The Bundestag dataset, for example, clustered mostly around terms such as “paragraph”, “article”, “commission” and “decision”. These terms are probably fairly distinctive, but they are hardly topical. The result for German Spiegel Online articles was even worse, Overview generated an almost perfect stop list for the language.
Uploading only the English-language, international section of Spiegel, on the other hand, gave me a fairly decent overview of recent political debates.
Summary
Looking at the state of these tools, it’s clear that there is no silver bullet. While Overview looks likely to become a great tool to handle documents at a large scale, it doesn’t yet offer the necessary range of visual analytics. Jigsaw has the right tools, but does not seem to scale very well.
Further alternatives would have been Nuix, which has been advertised quite heavily by the people involved in OffshoreLeaks, but seems rather expensive. DocumentCloud is starting to offer some rudimentary entity and timeline-based analysis views out of the box, while Solr continues to be a great solution for full-text search and faceting.
German language support, however, continues to be the biggest issue for all of these open source tools. The only freely available entity extractor appears to be a branch of Stanford NER which hasn’t been integrated into any of the tools mentioned in this post. While Germany has a number of top-notch computer linguistics faculties, none of them seems to feel the need to open up their resources to the public. Let’s talk about open access.